How to Use This Material
These are discussion questions created to go along with our Confluent Technical Fundamentals of Apache Kafka® course. They are designed to have you think more deeply about some of the content than can be achieved via the quick quizzes embedded within. Here are a few options on how to use them:
-
In an extended live session, your instructor may facilitate discussions of some questions among participants.
-
The questions are designed to be discussion questions, so if you can connect with a colleague or friend for a live discussion — consider Zoom or other video conferencing — you’ll get the most out of these questions.
-
Whether you’re working alone or discussing with others, review the question and give it serious though before expanding the Solution to see the intended solution and commentary related to each question.
Q1: How Do Producers Connect to Consumers?
Suppose you have a Kafka cluster; one producer, p0, producing to topic t0, with one partition; and one consumer c0, reading from topic t0. c0 read what p0 produced. How exactly are p0 and c0 connected? If you add another producer p1 (that also produces to topic t0), must you also add another consumer (e.g., c1) to read messages from p1?
Solution
This is one of the most basic scenarios possible—you may be playing with Kafka for fun or to get started, but this setup is not recommended in production. We have a single topic with only one partition, along with a producer and a consumer. Because there is only one partition, all messages that the producer produces will be written to that partition, p0. And because there is only a single consumer reading from t0 (note that c0 had to subscribe to topic t0), that consumer will be assigned to read from the sole partition.
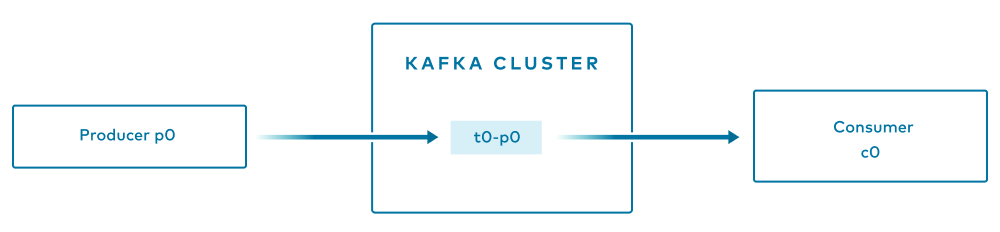
Should we add another producer, p1, which produces to the same topic, we do not need to add another consumer. The new producer p1 would write to the sole partition that exists. Consumer c0 is assigned to consume from the topic t0. Thus:
-
Messages from both producers will exist in the same partition (mixed, ordered by when they arrived, not by which producer sent them)
-
Consumer c0 would read messages from both producers in the order that they arrived at that partition
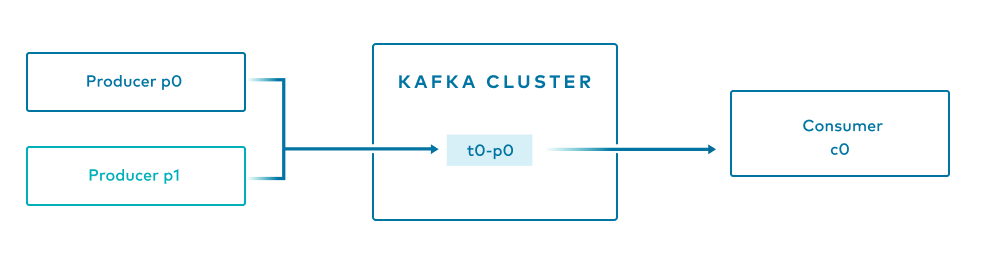
This brings us to the key takeaway—producers and consumers are decoupled. Producers write to logs; consumers read from logs. Consumers don’t know which producers produced what messages they are reading; producers don’t know which consumers (if any) will read what messages they produce. If you want to scale up production or consumption to improve performance of either, you can just add more producers or consumers and not worry about what’s going on on the other end.
Sometimes, people think there is a direct relationship between producers and consumers, perhaps because of how other systems and programming paradigms tie input and output together, but in Kafka, these two entities are independent.
Q2: Single Consumption or Multiple Consumption?
Suppose you have a Kafka cluster; one producer, p0, producing to topic t0, with one partition; and one consumer c0, reading from topic t0. Independent of the last question, suppose consumer c0 read message m0. Could another consumer c10, in another consumer group, also consume message m0?
Solution
c0 has read a given message, m0. Let’s back up to dissect how this happened:
-
First, some producer had to have written m0 to our sole partition.
-
Consumer c0 had to have been assigned to read from that sole partition.
-
Consumer c0 keeps track of a consumer offset for the sole partition, which is the offset of which message it will read next. Say that c0’s consumer offset for our lone partition was 17, and m0 was at offset 17.
-
So, c0 reads from offset 17 and gets m0. Since c0 has read from offset 17, it advances its consumer offset for the sole partition to 18.
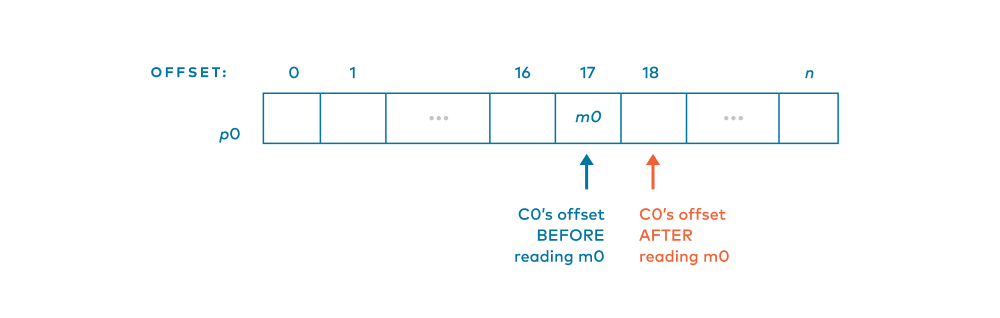
Notice that the message at offset 17 was not removed from the partition. Kafka logs are not queues; messages don’t get removed. It is best to think of consuming as reading messages.
Going back to the question, let’s assume that our other consumer c10 is assigned to consume from the same partition. Message m0 is still there, so whenever c10 has an offset of 17 and asks for messages, it will indeed read m0. This gets back to the key Kafka distinguishing feature of multiple consumption, powered by the fact that events are stored.
c10 was in a different consumer group from c0. Why would c10 consume a message that c0 already consumed? Each consumer group is doing something different with the same data. Maybe c0 consumed the message to accomplish something that demands an immediate response, like retrieving a mobile food order, prints an order slip that goes to a restaurant’s kitchen, and ensures the preparation of your lunch so that it’s waiting for you in 15 minutes on the dot. Maybe c10 is consuming lunch orders and analyzing them to tally what food was ordered during lunch at the restaurant. Perhaps it’s working with some other applications or systems to make sure that inventory is in good shape by dinnertime. In the next problem, we dive deeper into consumer groups.
Q3: Grouped Consumers Details
Suppose you have a topic with 3 partitions, p0, p1, and p2. Further, suppose we have consumer group g0 with consumers c0 and c1. No matter what further configuration you have, what is the same about c0 and c1? What are they doing differently?
Solution
In this case, both c0 and c1 are in the same consumer group. This means that they are performing the same logic as each other. But what is different is they are working with different data. The goal of a consumer group is to read all of the data from all of the topics to which its consumers are subscribed (and if all consumers in a group share the same logic, they share their topic subscription). Let’s simplify it this way: These consumers are subscribed to one topic, and these consumers are working to consume all of the data from all of the partitions of that topic.
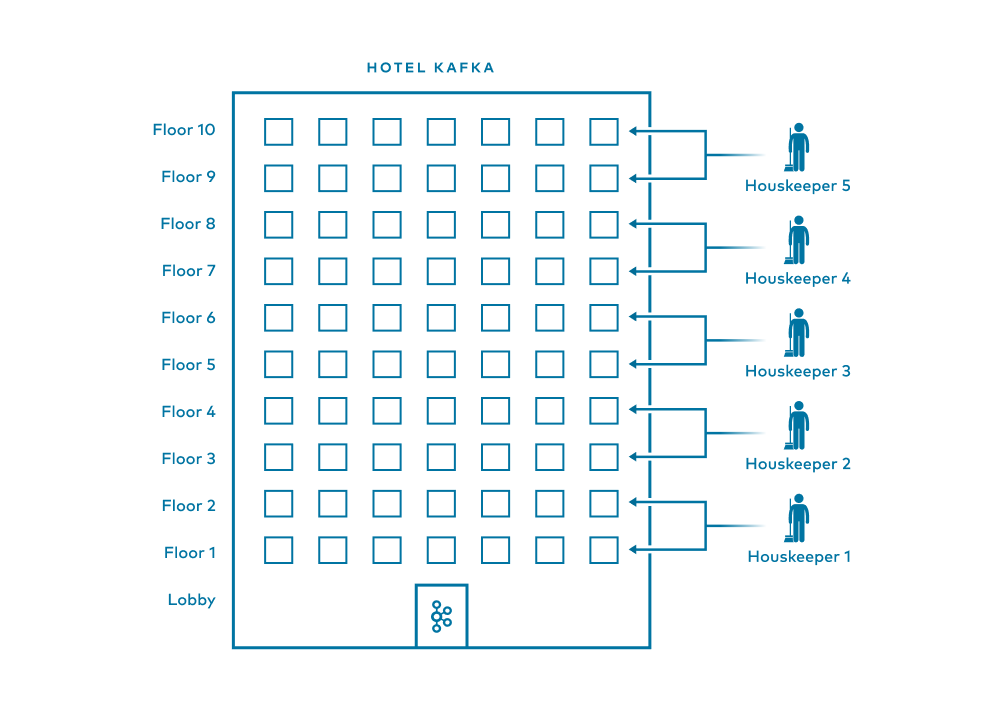
In a non-Kafka scenario, it’s as if we have a hotel with 10 floors of guest rooms. We might have a team of five housekeepers, each of whom must fully clean every assigned guest room alone (no teamwork is allowed within a single room in this scenario). No matter what, by the time it’s time for guests to arrive, all rooms on all 10 floors must be cleaned.
-
Housekeeper 1 on the team takes Floors 1 and 2 and cleans all the dirty rooms on those floors
-
Housekeeper 2 takes Floors 3 and 4 and cleans all the dirty rooms on those floors
-
This continues, i.e., Housekeeper 3 cleans Floors 5 and 6, Housekeeper 4 cleans Floors 7 and 8, and Housekeeper 5 cleans Floors 9 and 10
-
The housekeepers are a team, and they trust each other to perform the work
There is a division of labor wherein everyone on the team is doing the same task but on different “data.” In this metaphor, the consumers are the housekeepers, and their team is the consumer group. The hotel rooms are messages, and each floor is a partition. Each housekeeper (consumer) is assigned two partitions (floors).
Q4: Fixing a Broken Consumer/Partition Assignment
Suppose you have a topic with 3 partitions, p0, p1, and p2. Further, suppose you have consumer group g0 with consumers c0 and c1. Suppose at one point in time, we have only the following assignments: c1 is consuming from p0 and c1 is consuming from p2. What is the downside about this situation? Propose a fix.
Details
Now, we have this assignment of consumers to partitions:
-
c1 is consuming from p0
-
c1 is consuming from p2
But we have three partitions: p0, p1, and p2.
The consumer group as whole must be working together to consume from all partitions. In this setup, p1 isn’t getting any attention. That means all the ride requests on p1 aren’t getting matched to drivers and people are waiting in the rain. Or a bunch of food orders on p1 aren’t getting prepared and customers with limited lunch breaks will show up to find they have to wait another 15 minutes. Or all the hotel rooms on Floor 3 aren’t getting clean and people are going to find a mess upon check-in. We better consume from all the partitions. The easiest fix is to have c0 consuming from p1.
Q5: Understanding Consumer Offsets
Suppose you have a topic with 3 partitions, p0, p1, and p2. Further, suppose you have consumer group g0 with consumers c0 and c1. It’s the same situation as before. Suppose c1 just read the message at offset 12 in p0. What is its consumer offset for this partition? With your fix in mind, are there any other consumer offsets stored?
Solution
We first have the case that c1 just read the message at offset 12 in p0. Remember, consumers just read messages, leave them, and advance their offsets. So, c1 will set its offset in p0 to 13.
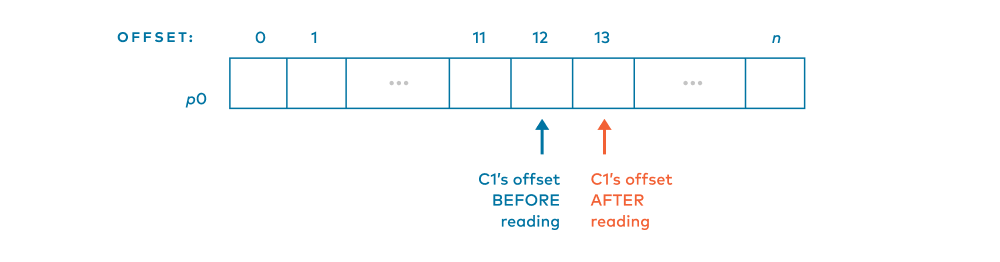
Think of it like a bookmark. If you just read Page 12 of a book and need to put the book down, you’re most likely going to put your bookmark at Page 13 to remind you where to pick up next time. If you’d prefer to put your bookmark where you last read, that’s reasonable. But the designers of Kafka had to make a decision and they made the decision that the consumer offset will tell the offset of the message to read next.
Are there other consumer offsets? Absolutely. Each consumer knows where it will read next in each partition to which it is assigned.
-
c0 has a consumer offset for where to read next in p1
-
c1 has a consumer offset for where to read next in p2
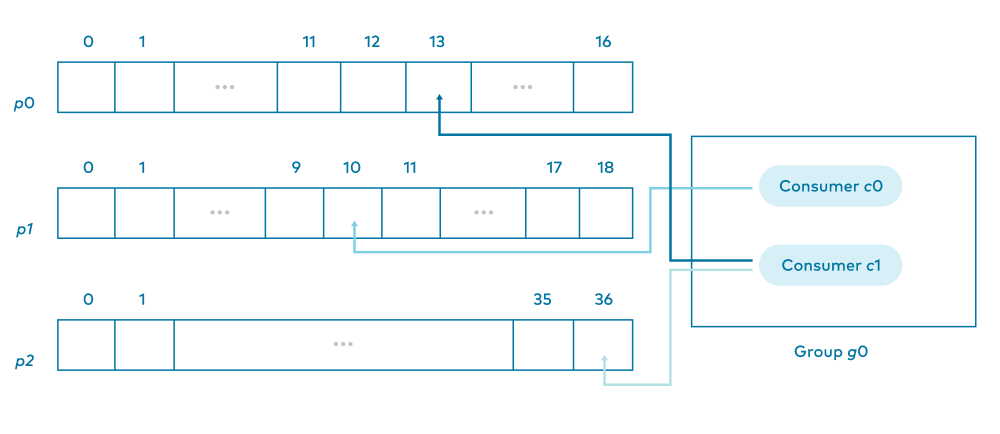
Back to the bookmark analogy: c0 is reading from p0 and p2. Maybe you’ve been reading two books at once. You are likely not on the same page in both of them. A consumer needs an offset for each individual partition, just like you need a separate bookmark for each book.
Q6: When Can Two Consumers Consume the Same Partition?
Suppose you have a topic with 3 partitions, p0, p1, and p2. Further, suppose you have consumer group g0 with consumers c0 and c1. You know that c1 is consuming from p0. Can c0 consume from p0? If so, why? If not, how can you change the setup to allow another consumer to consume from p0?
Solution
c1 is consuming from p0, and we propose c0 is also consuming from p0.
Before going into the answer, let’s go back to that hotel rooms and housekeepers metaphor. This is like having Housekeeper 1 assigned to clean all of the rooms on Floors 1 and 2 (as stated above), but another housekeeper, such as Housekeeper 6, also assigned to clean all of the rooms on Floor 1. Housekeeper 6’s shift starts after Housekeeper 1 is done for the day. What’s going to happen? Housekeeper 6 goes into every room on Floor 1 and finds it clean already? Could Housekeeper 6 re-clean each room? Maybe. But cleaning products, time, effort, and laundry resources are being wasted.
In the Kafka world, the answer would be no. If two consumers in the same group were to consume from the same partition, that would mean reprocessing messages in exactly the same way. At best, that wastes resources and could bother customers with duplicate notifications or ads. At worst, a stakeholder loses money or resources. Simply put, Kafka doesn’t not allow more than one consumer in a consumer group to consume from the same partition.
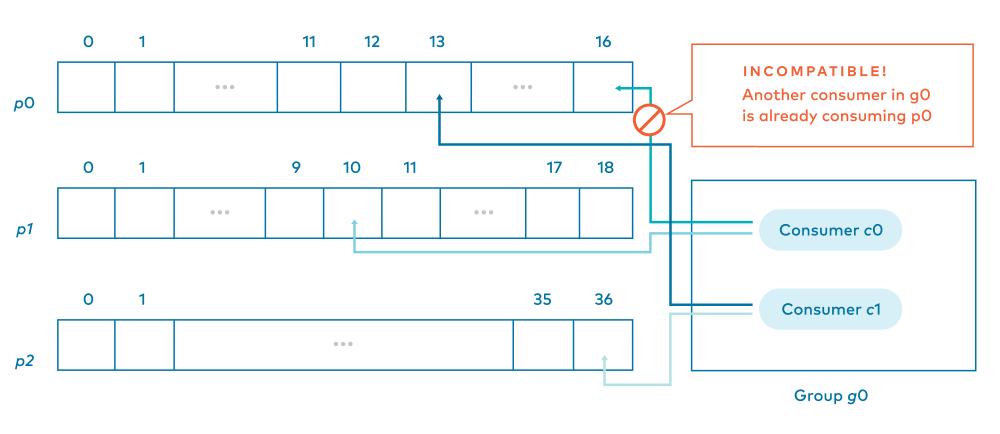
Note that this doesn’t go both ways. A single consumer in a group could consume from more than one partition.
How can we change the problem setup to allow c0 also to consume from p0? c0 can be in a different group. This way, it’s working the data differently from p0, not reprocessing it in the same way. If this sounds like a lot to manage, the good news is that Kafka takes care of all consumer/partition assignments for you. It won’t let you break the rules. It’ll even adjust things when a component goes down.
Q7: Understanding Compaction
This is one of the logs from the second of the quick quizzes:
| Segment | seg0 | seg1 | active | |||||
|---|---|---|---|---|---|---|---|---|
| Offset | 3 | 6 | 7 | 9 | 12 | 13 | 14 | 15 |
| Key | 7 | 2 | 4 | 6 | 4 | 9 | 5 | 9 |
| Value | a | b | c | d | e | f | g | h |
| Age (days) |
12 | 11 | 9 | 8 | 6 | 4 | 3 | 1 |
This was specifically from a problem about the deletion retention policy. What if, instead of using deletion, the compaction retention policy were turned on? Which records would remain in this log after compaction?
Solution
Whereas the deletion retention policy deals with the ages of records, compaction cares about the keys of records. (Note that you can have both compaction and deletion running as well.)
Compaction removes records for which there is a newer record with the same key. The record at offset 7, with key 4, is removed, as there is a newer instance of a record with key 4 at offset 12.
You might also think that the record at offset 13, with key 9, would be removed due to the record with key 9 at offset 15. This is a reasonable idea. However, these records are part of the active segment, and compaction does not touch the active segment, so the record at offset 13 does remain in the log. We go into more details on this in both in our Administrator and Developer courses; some great discussions related to this can and do often happen there!
To summarize simply, all records in this log except the record at offset 7 would remain after compaction ran.
Check out our Training & Certification page to learn more about our other Training offerings and sign up.